

Ijraset Journal For Research in Applied Science and Engineering Technology
Object Detection and Speech Recognition Using Machine Learning
Authors: Riyaz Ahmed, B. Pradeep , Mr V. Narasimha
DOI Link: https://doi.org/10.22214/ijraset.2024.59341
Certificate: View Certificate
Abstract
This paper presents a comprehensive project that integrates computer vision, natural language processing, and deep learning techniques to enhance object and speech recognition capabilities. The proposed system leverages the OpenCV library to identify objects within an input image, subsequently generating a new image annotated with the names of the recognized objects. Furthermore, the project incorporates the pyttsx3 module to convert the identified object names into speech, providing an additional layer of accessibility. The system extends its functionality by incorporating a contextual summarization component. Upon user input of contextual information related to the recognized objects, the system utilizes a language model, Large Language Model (LLM), to summarize the provided context. This summarization process contributes a Retrieval Augmented Generation (RAG) element, offering a quick and efficient overview of the given information. The seamless integration of object identification, speech synthesis, and contextual summarization enhances the user experience, making the system versatile and accessible. The proposed solution finds application in various domains such as assistive technology, image recognition, and natural language processing. The experimental results demonstrate the effectiveness and accuracy of the system, showcasing its potential contributions to the field of machine learning and deep learning application.
Introduction
I. INTRODUCTION
The amalgamation of, natural language processing, and deep learning has led to significant advancements in image understanding and communication systems. This paper introduces a novel project that seamlessly integrates these technologies to create an intelligent system for object and speech recognition, with an added dimension of contextual summarization. The envisioned system addresses necessity for enhanced accessibility and comprehension in human-computer interactions by leveraging state-of-the-art tools and frameworks. The core functionality of the system is built upon the widely-used OpenCV library, enabling the identification of objects within a given image. Upon recognizing objects, the system generates a visually annotated image, enriching the user experience and aiding in information assimilation. In tandem with object recognition, the project incorporates the pyttsx3 module to convert identified object names into synthesized speech. This auditory output not only caters to users with visual impairments but also provides an additional layer of interaction, making the system versatile and inclusive. Taking a step further, the system integrates contextual summarization by utilizing a Large Language Model (LLM). Users can input contextual information related to the recognized objects, and the system employs the LLM to generate concise summaries, introducing a Retrieval Augmented Generation (RAG) element. This feature contributes to a more comprehensive understanding of the information and facilitates efficient decision-making. The overarching goal of this project is to demonstrate the seamless integration of various technologies to create a robust, accessible, and intelligent system for object and speech recognition. The subsequent sections of this paper delve into the methodology, experimental results, and potential applications, showcasingThe efficacy and adaptability of the suggested solution in the landscape of machine learning and deep learning applications.
II. OBJECT DETECTION
Object detection is a critical element within our intelligent system, seamlessly blending advanced computer vision techniques and adaptability to various scenarios. Let's explore the two facets of our comprehensive object detection capabilities:
A. Static Image Object Detection
In the realm of static image object detection, our system harnesses the sophisticated capabilities of OpenCV's advanced computer vision techniques.
This enables the precise identification and recognition of objects within pre-captured images, forming the foundational capability for subsequent processes within the system. This static image object detection not only establishes a robust groundwork but also ensures accuracy and reliability in handling non-changing visual content.
B. Real-time Object Detection with Webcam Feed
Expanding beyond static scenarios, our system seamlessly integrates real-time object detection through live webcam feeds. By continuously analyzing successive frames from the webcam, the system achieves immediate and accurate identification of objects within the camera's field of view. This dynamic approach showcases adaptability to changing environments, making it particularly suitable for applications such as augmented reality experiences and live surveillance scenarios where real-time responsiveness is crucial.
C. Dual-Mode Object Detection Capabilities
The system excels in seamlessly transitioning between static and dynamic scenarios, offering comprehensive coverage across a wide range of applications. This dual-mode object detection ensures adaptability and versatility, capable of handling both pre-captured images and live video streams. Whether the need is for detailed analysis of static content or real-time responsiveness in dynamic environments, our system's dual-mode capabilities provide a flexible and encompassing solution for diverse use cases.
III. SINGLE SHOT DETECTOR
Lately, the domain of computer vision has witnessed a transformative shift propelled by advancements in deep learning methodologies. Among the myriad of innovations, the Single Shot Multibox Detector (SSD) stands out as a pioneering approach to object detection, offering unparalleled speed and accuracy. Developed to address the limitations of conventional object detection techniques, SSD amalgamates the efficiency of Convolutional Neural Networks (CNNs) with the elegance of region proposal networks, establishing itself as a cornerstone in real-time object detection. Traditional object detection methods often rely on a two-step process involving region proposal and subsequent classification. SSD, in contrast, adopts a one-shot approach, streamlining the workflow and significantly accelerating inference speed.
This unique methodology is particularly advantageous in scenarios where real-time detection is imperative, such as in autonomous vehicles, surveillance systems, and interactive environments. At the heart of SSD lies the architecture's adeptness in simultaneously predicting object categories and bounding box coordinates for multiple predefined anchor boxes across different spatial scales. This multi-scale feature allows SSD to excel in detecting objects of varying sizes within a single pass, contributing to its robustness and adaptability in diverse contexts.
Moreover, the architecture's flexibility extends to accommodating different base CNN architectures, permitting practitioners to tailor SSD to their specific needs and computational constraints. The modular design of SSD enables its seamless integration into a myriad of applications, from resource-constrained edge devices to high-performance computing environments. As the boundaries of computer vision continue to expand, SSD remains at the forefront, driving innovation in real-time object detection. This paper delves into the intricacies of SSD, exploring its architectural nuances, operational principles, and the manifold applications where its efficiency and accuracy converge to redefine the landscape of object detection.
IV. RETRIEVAL AUGMENTED GENERATION (RAG)
In the ever-expanding landscape of information retrieval, the Retrieval Augmented Generation (RAG) mechanism emerges as a transformative paradigm, reshaping how systems generate contextualized summaries. RAG integrates retrieval-based strategies into traditional generation models.
This innovative approach enhances the depth and relevance of generated content by incorporating contextual cues derived from user-supplied queries, thereby ushering in a new era of nuanced content summarization. Utilization of RAG in Our Intelligent System: At the core of our intelligent system lies the distinctive feature of Retrieval Augmented Generation (RAG), a mechanism designed to imbue identified objects within visual content with contextually rich summaries. The synergy between RAG and our system is manifested when users contribute additional context related to the recognized objects. In response, the system seamlessly employs a Large Language Model (LLM) to orchestrate the contextual summarization process. The LLM, a sophisticated language processing model, dynamically synthesizes user-supplied context and information about identified objects. This fusion culminates in the generation of concise and contextually relevant summaries in real-time.
Through this integration, our system transcends traditional information retrieval methods, providing users not only with raw data about identified objects but also with coherent and informative narratives tailored to their specific queries.
Advancing User Interaction: The incorporation of RAG into our system signifies a paradigm shift in user interaction with visual content. Beyond the mere identification of objects, our system empowers users to delve into the intricacies of their visual data, fostering a more immersive and enriched experience.
The contextual summaries generated by RAG not only enhance user comprehension but also enable more meaningful and targeted exploration of complex visual datasets. In essence, the amalgamation of RAG and our intelligent system underscores our commitment to advancing user-centric design in information retrieval. By harnessing the power of contextual summarization, we strive to provide users with a comprehensive and personalized understanding of visual content, marking a significant stride toward a more intuitive and responsive intelligent system.insights, making the intelligent system a versatile tool for contextualized information retrieval.
V. SPEECH RECOGNITION
Speech recognition, a pivotal aspect of natural language processing, has undergone significant advancements in recent years, transforming the way we interact with technology. This technology enables machines to interpret and comprehend spoken language, converting it into text or actionable commands.
The applications of speech recognition span a wide range of fields, including virtual assistants, transcription services, and assistance features for people with disabilities.
Speech recognition, a pivotal aspect of natural language processing, has undergone significant advancements in recent years, transforming the way we interact with technology. This technology enables machines to interpret and comprehend spoken language, converting it into text or actionable commands.
The applications of speech recognition span a wide range of fields, including virtual assistants, transcription services, and assistance features for people withdisabilities.
Incorporating an essential facet of auditory interaction, our system employs the pyttsx3 module for seamless speech synthesis. After identifying objects within images through advanced computer vision techniques, the system utilizes pyttsx3 to convert the recognized object names into clear and natural speech. This integration enhances user accessibility by providing audible feedback, making the system not only visually informative but also inclusively engaging for users. The pyttsx3 module's capability to convert textual information into speech ensures a versatile and user-friendly interface, contributing to a more enriched and accessible user experience within the intelligent system.
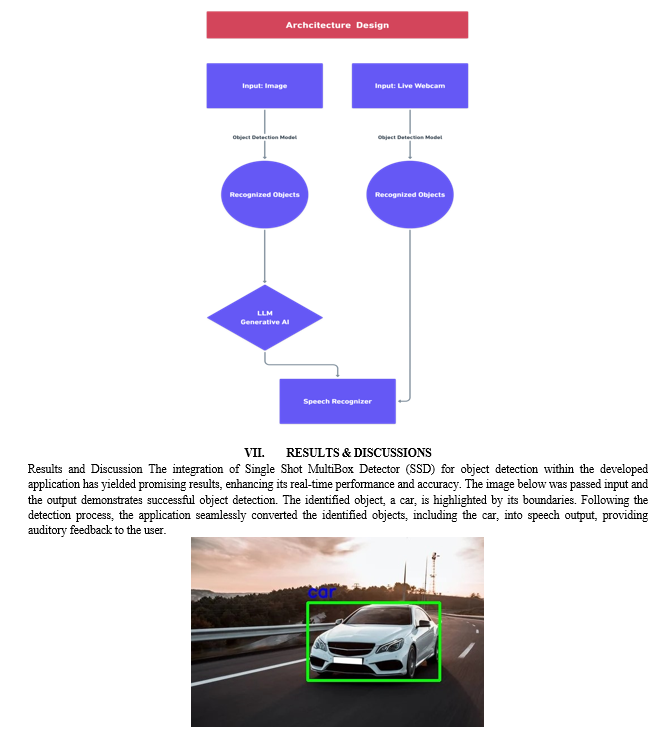
VI. ARCHITECTURE DESIGN
The proposed architecture integrates the Single Shot Multibox Detector (SSD) for robust object detection in both static images (Module 1) and real-time webcam feeds (Module 2). SSD's efficiency in detecting multiple objects simultaneously ensures a responsive and accurate system.
For speech synthesis (Module 4), the system utilizes pyttsx3 to convert text-based responses into spoken output. pyttsx3 provides a straightforward interface for text-to-speech conversion, offering ease of use and flexibility. Module 3 incorporates the Gemini Language Model (LLM) to handle context summarization. The LLM, known for its advanced natural language processing capabilities, assimilates the identified objects from static images alongside user context to generate concise and coherent summarized responses.
This architecture, now leveraging pyttsx3 for speech synthesis, combines the efficiency of SSD in object detection, the simplicity of pyttsx3 for speech conversion, and the Gemini LLM for context-aware summarization. The modular design ensures adaptability, enabling updates or replacements of individual components without disrupting the overall system. This integrated approach aims to provide users with a seamless and intelligent interaction experience at the convergence of image understanding, language modeling, and spoken communication.

In addition to its object detection and speech synthesis capabilities, the application features an advanced augmentation function facilitated by contextual cues. Upon receiving static images with accompanying context from the user, the application extends its functionality by incorporating contextual understanding into the object detection process. Notably, when provided with contextual information alongside the image, the application utilizes large language models, such as those provided by Google Gemini, to generate summarized responses. This enhancement significantly enriches the user experience by providing more insightful and relevant interpretations of the detected objects within the given context. The integration of contextual augmentation represents a notable improvement in the application's functionality, enabling more sophisticated interactions and expanding its utility in various domains requiring nuanced understanding and interpretation of visual data. This feature aligns with the concept of RAG (Retrieval-Augmented Generation), allowing for more nuanced and contextually relevant responses to be generated based on the input and contextual cues provided by the user.
After generating the summarized response based on the contextual cues and detected objects, the application seamlessly converts the synthesized response into speech output. This integration of speech synthesis further enhances the user experience by providing auditory feedback that complements the contextual understanding and interpretation of the visual data. By combining contextual augmentation with speech synthesis, the application offers a comprehensive and intuitive interface for users, catering to a wide range of needs and preferences. This integrated approach not only improves accessibility but also facilitates more natural and immersive interactions, making the application well-suited for various real-world applications, including assistive technologies and interactive system.
Conclusion
In conclusion, the proposed architecture seamlessly integrates advanced technologies to create a comprehensive system for image understanding, context summarization, and spoken communication. Leveraging the Single Shot Multibox Detector (SSD) for efficient object detection in static images and real-time webcam feeds ensures accurate and responsive identification of multiple objects. The use of pyttsx3 for speech synthesis streamlines the conversion of text-based responses into clear and natural spoken output, enhancing the user experience. The incorporation of Googles gemini Language Model (LLM) for context summarization adds a layer of sophistication, allowing the system to generate concise and coherent summaries based on identified objects and user context. This synthesis of cutting-edge technologies in object detection, speech synthesis, and natural language processing is designed with modularity in mind, enabling individual components to be updated or replaced without disrupting the overall system functionality. This architecture represents a holistic approach to human-machine interaction, providing users with a seamless and intelligent experience at the intersection of visual perception and spoken communication. The convergence of these technologies not only showcases their individual strengths but also highlights the potential for creating sophisticated, adaptable systems that cater to diverse user needs.
References
[1] R. Girshick, \"Fast R-CNN,\" in Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, Dec. 2015, pp. 1440-1448. DOI: 10.1109/ICCV.2015.169. [2] S. Ren et al., \"Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks,\" in IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 39, no. 6, pp. 1137-1149, June 2017. DOI: 10.1109/TPAMI.2016.2577031. [3] J. Redmon et al., \"YOLOv3: An Incremental Improvement,\" in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, June 2018, pp. 8342-8351. DOI: 10.1109/CVPR.2018.00873. [4] W. Liu et al., \"SSD: Single Shot MultiBox Detector,\" in Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, Oct. 2016, pp. 21-37. DOI: 10.1007/978-3-319-46448-0_2. [5] T.-Y. Lin et al., \"Focal Loss for Dense Object Detection,\" in Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, Oct. 2017, pp. 2980-2988. DOI: 10.1109/ICCV.2017.324.
Copyright
Copyright © 2024 Riyaz Ahmed, B. Pradeep , Mr V. Narasimha. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET59341
Publish Date : 2024-03-23
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online